
Mind the Mean
The arithmetic mean is a commonly used measure for summarizing data. Simply put, the mean is equal to the sum of values in a set divided by the number of values in the set.


While the mean can be informative, there are certain situations when the mean is not a good representation of a set of data. In this post, I will share two cases where the mean is not an appropriate measure for summarizing data, along with suggestions for what you could report instead.
Case #1: When your data has extreme values
An extreme value is a value in a set of data that is either very large or very small in comparison to the rest (or majority) of the data. Extreme values in a set of data can significantly influence the mean and can give you a false impression of the data. Let’s look at an example:
The data below represent the number of miles traveled to and from school each day by a sample of 10 students. Most students reported traveling between 2 to 9 miles a day. One student, however, lives in a different city, so their daily commute to and from school is 50 miles!

The results were analyzed, and the mean was obtained.

Because of the extreme value (50), the mean of the set of data is 9.5 miles, which is larger than 9 of the 10 values in the set! In this case, the mean would not be an appropriate measure to report, because the data contains an extreme value.
Possible Solution: Use the median
If you suspect you have extreme values in a set of data, first, plot the data to find the extreme value(s). Two plots that are useful for finding extreme values and other anomalies in a data set are scatter plots and box plots.
Box plot

Scatter plot

Next, calculate the median. The median is a value that divides a distribution of data in half so that half of all values in a set of data are above it, and half are below it. To find the median of a set of data:
1. Arrange all the values in the set in ascending numerical order.

2. If there are an odd number of values in the set of data, then the median is equal to the middle value. (Note: the number ‘1’ was added to the set of data for demonstration purposes only.)
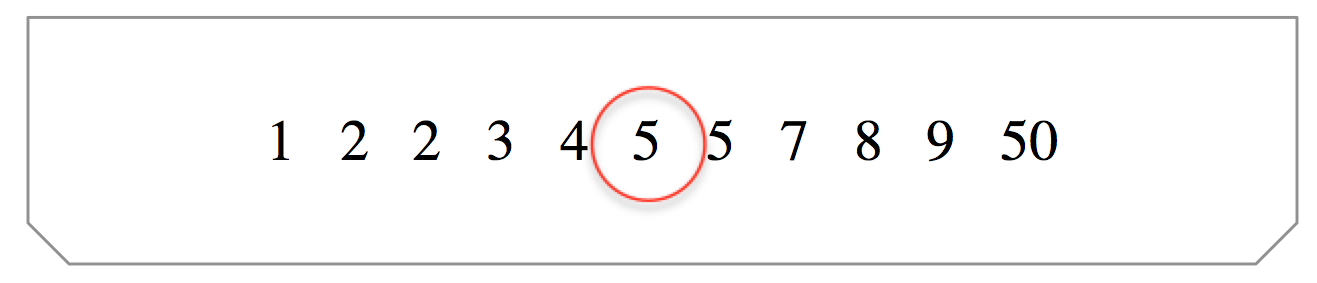
Picture of values in set arranged in ascending order (odd number of values).
3. If there are an even number of values in the set of data, then the median will be equal to the average of the two middle values.


The median can be interpreted in the following way: Half of the students in the sample travel less than 5 miles to and from school each day, and half of the students in the sample travel more than 5 miles to and from school each day.
When your data contains extreme values, it is more useful to report the median instead of the mean because the median is less affected by extreme values and will give you a more accurate representation of the data.
Case #2: If your data are nominal
A nominal variable is a variable that classifies observations into distinct categories, but the categories do not have a natural order. For example, marital status is a nominal variable that can be classified into five subcategories: 1 = Single (never married), 2 = Married, 3 = Separated, 4 = Widowed, and 5 = Divorced. The five subcategories, however, are attributes composing the variable marital status and cannot be quantified in a meaningful manner. Therefore, even if you rearrange the order in which the categories are listed (e.g., 1 = Single, 2 = Married, 3 = Separated, 4 = Widowed, 5 = Divorced to 1 = Widowed, 2 = Married, 3 = Separated, 4 = Divorced, 5 = Single), the variable marital status will still be interpreted the same way (i.e., a nominal variable comprising of 5 categories). In this case, trying to calculate the mean would not be appropriate because the numeric values you assign to different categories are used for labeling purposes only and have no quantitative significance.
Let’s look at an example using the variable marital status:
Say you are a researcher at a nonprofit organization, and you are asked to develop a demographics survey to better understand the marital status breakdown of your clients. One question on the survey asks clients to answer the following:

You assign value labels to each of the categories (e.g., Single = 1, Married = 2, Separated = 3 etc…). The data below represent the responses you received from the survey sample (30 clients).

You analyze the results and obtain the mean, a value of 3.70. You begin writing up your results when a colleague asks you, “How would you interpret a mean marital status of 3.70?” You then realize that it does not make sense to compute the mean for this variable because there is no way to interpret an average of 3.70. Calculating the mean of a nominal variable produces nonsensical results because the categories cannot be quantified in a meaningful way.
Possible Solution(s): Use frequency counts or percentages
The best way to report nominal data is to use frequency counts or percentages. Frequency tables and bar graphs are two popular choices for displaying nominal data.
Frequency Table

Bar Graph

What are some other reasons not to use the mean as a measure for summarizing data? Please share your thoughts in the comments section below.